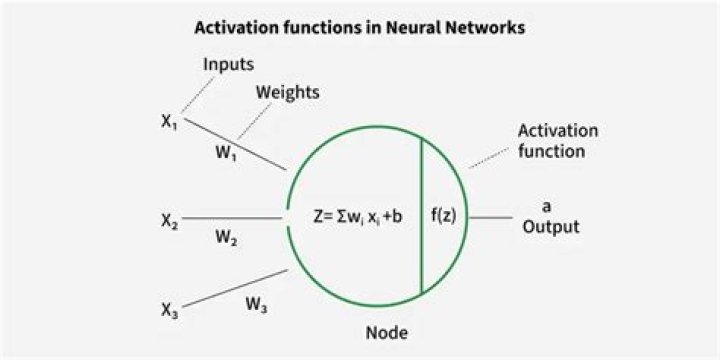
Activation functions are mathematical equations that determine the output of a neural network. The function is attached to each neuron in the network, and determines whether it should be activated (“fired”) or not, based on whether each neuron's input is relevant for the model's prediction..
Consequently, what is the role of activation function in neural network?
Definition of activation function:- Activation function decides, whether a neuron should be activated or not by calculating weighted sum and further adding bias with it. The purpose of the activation function is to introduce non-linearity into the output of a neuron.
Beside above, what are activation functions and why are they required? Activation functions are really important for a Artificial Neural Network to learn and make sense of something really complicated and Non-linear complex functional mappings between the inputs and response variable. They introduce non-linear properties to our Network.
Similarly, you may ask, what is the purpose of the activation function?
The purpose of an activation function is to add some kind of non-linear property to the function, which is a neural network. Without the activation functions, the neural network could perform only linear mappings from inputs x to the outputs y.
What is an activation function in deep learning?
In a neural network, the activation function is responsible for transforming the summed weighted input from the node into the activation of the node or output for that input. In this tutorial, you will discover the rectified linear activation function for deep learning neural networks.
Related Question Answers
How do activation functions work?
Role of the Activation Function in a Neural Network Model The activation function is a mathematical “gate” in between the input feeding the current neuron and its output going to the next layer. It can be as simple as a step function that turns the neuron output on and off, depending on a rule or threshold.Is Softmax an activation function?
Softmax is an activation function. Other activation functions include RELU and Sigmoid. It computes softmax cross entropy between logits and labels. Softmax outputs sum to 1 makes great probability analysis.Why ReLU is non linear?
ReLU is not linear. The simple answer is that ReLU output is not a straight line, it bends at the x-axis. In simple terms, linear functions allow you to dissect the feature plane using a straight line. But with the non-linearity of ReLU s, you can build arbitrary shaped curves on the feature plane.What does Softmax layer do?
A softmax layer, allows the neural network to run a multi-class function. In short, the neural network will now be able to determine the probability that the dog is in the image, as well as the probability that additional objects are included as well.Why do we use non linear activation function?
To make the incoming data nonlinear, we use nonlinear mapping called activation function. Non-linearity is needed in activation functions because its aim in a neural network is to produce a nonlinear decision boundary via non-linear combinations of the weight and inputs.What is the activation function for classification?
ReLU (Rectified Linear Unit) Activation Function The ReLU is the most used activation function in the world right now. Since, it is used in almost all the convolutional neural networks or deep learning.What is Softplus?
Softplus is an alternative of traditional functions because it is differentiable and its derivative is easy to demonstrate. Besides, it has a surprising derivative! Softplus function dance move (Imaginary) Softplus function: f(x) = ln(1+ex) And the function is illustarted below.Why is ReLU the best activation function?
1 Answer. The biggest advantage of ReLu is indeed non-saturation of its gradient, which greatly accelerates the convergence of stochastic gradient descent compared to the sigmoid / tanh functions (paper by Krizhevsky et al). But it's not the only advantage.Why does CNN use ReLU?
What is the role of rectified linear (ReLU) activation function in CNN? ReLU is important because it does not saturate; the gradient is always high (equal to 1) if the neuron activates. As long as it is not a dead neuron, successive updates are fairly effective. ReLU is also very quick to evaluate.What is the activation function in regression?
the most appropriate activation function for the output neuron(s) of a feedforward neural network used for regression problems (as in your application) is a linear activation, even if you first normalize your data.What is ReLU in deep learning?
ReLU stands for rectified linear unit, and is a type of activation function. Mathematically, it is defined as y = max(0, x). Visually, it looks like the following: ReLU is the most commonly used activation function in neural networks, especially in CNNs.What is neural activation?
In a neural network, each neuron has an activation function which speci es the output of a. neuron to a given input. Neurons are `switches' that output a `1' when they are su ciently. activated, and a `0' when not. One of the activation functions commonly used for neurons is the.What is the difference between Softmax and sigmoid?
Getting to the point, the basic practical difference between Sigmoid and Softmax is that while both give output in [0,1] range, softmax ensures that the sum of outputs along channels (as per specified dimension) is 1 i.e., they are probabilities. Sigmoid just makes output between 0 to 1.Who invented ReLU?
In 1991 Jerome Friedman, a statistician from Stanford, presented an automatic nonlinear regression method called Multivariate Adaptive Regression Splines (MARS). The terms in this model are of the form max(0,x-t) and max(0,t-x). ReLU is obviously just using the term max(0,x-0) = max(0,x).What is Adam Optimizer?
Adam [1] is an adaptive learning rate optimization algorithm that's been designed specifically for training deep neural networks. The algorithms leverages the power of adaptive learning rates methods to find individual learning rates for each parameter.What is ReLU layer in CNN?
The ReLu (Rectified Linear Unit) Layer ReLu refers to the Rectifier Unit, the most commonly deployed activation function for the outputs of the CNN neurons. Mathematically, it's described as: Unfortunately, the ReLu function is not differentiable at the origin, which makes it hard to use with backpropagation training.Why ReLU is not used in output layer?
ReLU generally not used in RNN because they can have very large outputs so they might be expected to be far more likely to explode than units that have bounded values.Why is ReLU used?
The ReLU function is another non-linear activation function that has gained popularity in the deep learning domain. ReLU stands for Rectified Linear Unit. The main advantage of using the ReLU function over other activation functions is that it does not activate all the neurons at the same time.What is weight in neural network?
Weight is the parameter within a neural network that transforms input data within the network's hidden layers. As an input enters the node, it gets multiplied by a weight value and the resulting output is either observed, or passed to the next layer in the neural network.