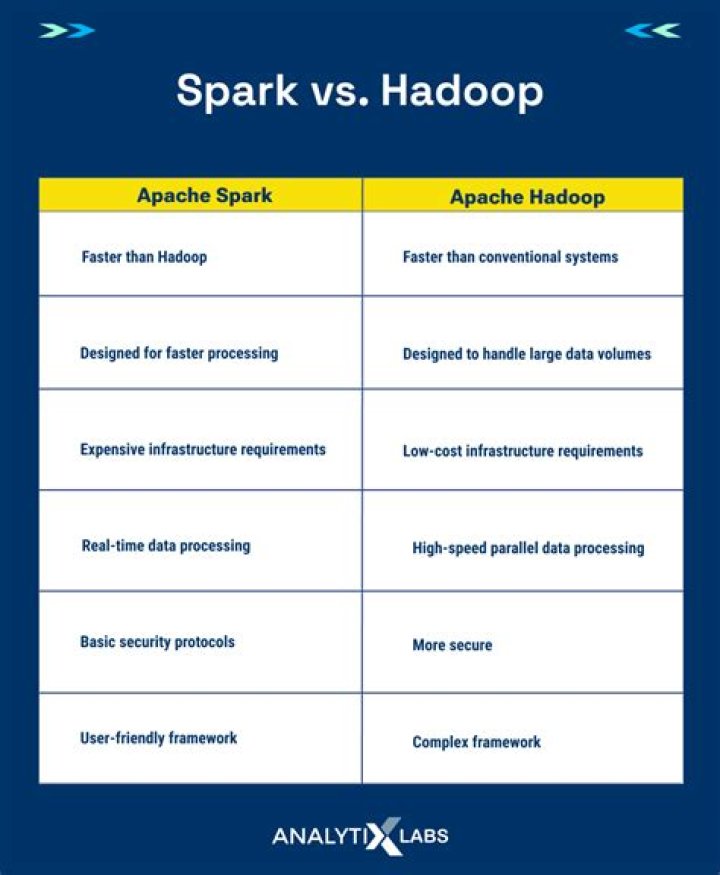
Apache Spark –Spark is lightning fast cluster computing tool. Apache Spark runs applications up to 100x faster in memory and 10x faster on disk than Hadoop. Because of reducing the number of read/write cycle to disk and storing intermediate data in-memory Spark makes it possible..
Furthermore, which is better to learn spark or Hadoop?
The first and main difference is capacity of RAM and using of it. Spark uses more Random Access Memory than Hadoop, but it “eats” less amount of internet or disc memory, so if you use Hadoop, it's better to find a powerful machine with big internal storage.
Subsequently, question is, what is better than Hadoop? The basic feature of spark that makes it better than hadoop is that it uses in-memory computing system. Spark can run on top of HDFS to leverage the distributed replication storage. Spark can be used along with MapReduce in the Same Hadoop cluster or can be used alone as a processing framework.
Subsequently, question is, what is difference between Hadoop and Spark?
Hadoop is designed to handle batch processing efficiently whereas Spark is designed to handle real-time data efficiently. Hadoop is a high latency computing framework, which does not have an interactive mode whereas Spark is a low latency computing and can process data interactively.
Is spark better than MapReduce?
The biggest claim from Spark regarding speed is that it is able to "run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk." Spark could make this claim because it does the processing in the main memory of the worker nodes and prevents the unnecessary I/O operations with the disks.
Related Question Answers
Should I learn Hadoop before spark?
No, it is not necessary to learn Hadoop before Apache Spark, however having the basic uderstanding of Hadoop Distributed File System (HDFS) will add an advantage as you might require it while learning Spark.Does spark need Hadoop?
Yes, Apache Spark can run without Hadoop, standalone, or in the cloud. Spark doesn't need a Hadoop cluster to work. Spark can read and then process data from other file systems as well. HDFS is just one of the file systems that Spark supports.Does spark replace Hadoop?
Spark can never be a replacement for Hadoop! Spark is a processing engine that functions on top of the Hadoop ecosystem. Both Hadoop and Spark have their own advantages. Hadoop has two phases HDFS+MapReduce; HDFS is used for storing and MapReduce for processing data.Is Hadoop outdated?
No, Hadoop is not outdated. There is still no replacement for Hadoop ecosystem. HDFS is still the most reliable storage system in world and more than 50% of the world's Data has been moved to Hadoop.Why spark is used in Hadoop?
Features of Apache Spark Speed − Spark helps to run an application in Hadoop cluster, up to 100 times faster in memory, and 10 times faster when running on disk. This is possible by reducing number of read/write operations to disk. It stores the intermediate processing data in memory.What is replacing Hadoop?
Apache Spark- Top Hadoop Alternative Spark is a framework maintained by the Apache Software Foundation and is widely hailed as the de facto replacement for Hadoop. The most significant advantage it has over Hadoop is the fact that it was also designed to support stream processing, which enables real-time processing.Why spark is faster than Hadoop?
The biggest claim from Spark regarding speed is that it is able to "run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk." Spark could make this claim because it does the processing in the main memory of the worker nodes and prevents the unnecessary I/O operations with the disks.How do you become a spark developer?
Required Skills for Spark Developer A clear understanding of each component of Hadoop ecosystem like HBase, Pig, Hive, Sqoop, Flume, Oozie, etc. Knowledge of Java is essential for a Spark developer. Excellent analytical and problem-solving skills. Hands on knowledge of scripting languages like Python or Perl.Does spark store data?
Spark is not a database so it cannot "store data". It processes data and stores it temporarily in memory, but that's not presistent storage. Spark can access data that's in: SQL Databases (Anything that can be connected using JDBC driver)What exactly is spark?
Apache Spark is an open source, general-purpose distributed computing engine used for processing and analyzing a large amount of data. Just like Hadoop MapReduce, it also works with the system to distribute data across the cluster and process the data in parallel.What is the use of spark?
Spark is a general-purpose distributed data processing engine that is suitable for use in a wide range of circumstances. On top of the Spark core data processing engine, there are libraries for SQL, machine learning, graph computation, and stream processing, which can be used together in an application.Does spark run MapReduce?
MapReduce: Compatibility. Apache Spark can run as a standalone application, on top of Hadoop YARN or Apache Mesos on-premise, or in the cloud. Spark supports data sources that implement Hadoop InputFormat, so it can integrate with all of the same data sources and file formats that Hadoop supports.Is Hadoop dead?
While Hadoop for data processing is by no means dead, Google shows that Hadoop hit its peak popularity as a search term in summer 2015 and its been on a downward slide ever since.Is Spark built on top of Hadoop?
No, Spark is not a part of the Hadoop Eco System, Hadoop and Spark are separate Frameworks for data processing. But Spark may be run at the top of the hadoop cluster and can use Hadoop features like Hadoop distributed file system and YARN.Is spark a tool?
Apache Spark defined Apache Spark is a data processing framework that can quickly perform processing tasks on very large data sets, and can also distribute data processing tasks across multiple computers, either on its own or in tandem with other distributed computing tools.What is Big Data Spark?
What is Spark in Big Data? Basically Spark is a framework - in the same way that Hadoop is - which provides a number of inter-connected platforms, systems and standards for Big Data projects. Like Hadoop, Spark is open-source and under the wing of the Apache Software Foundation.What is Hdfs in spark?
HDFS is a distributed file system designed to store large files spread across multiple physical machines and hard drives. Spark is a tool for running distributed computations over large datasets. Spark is a successor to the popular Hadoop MapReduce computation framework.Is Hadoop the future?
Hadoop is a Big Data technology that enables distributed storage and computing of data. Hadoop overcomes the shortcomings in traditional RDBMS system. Also, it is cheaper than the conventional system. Hence the Hadoop market is growing day by day and so the future of Hadoop is very bright.Is Hadoop a database?
Hadoop is not a type of database, but rather a software ecosystem that allows for massively parallel computing. It is an enabler of certain types NoSQL distributed databases (such as HBase), which can allow for data to be spread across thousands of servers with little reduction in performance.